Comment apprendre à une machine à conduire

Il faut connaître le code de la route, être capable d'évaluer correctement les situations de circulation difficiles en une fraction de seconde et réagir en conséquence. Quiconque vient de suivre sa première leçon de conduite peut confirmer que rien de tout cela n'est anodin. Et il en va de même pour ceux qui tentent de l'enseigner à une machine.
Déverrouiller les synergies

Il existe plusieurs approches pour cela.
L'une d'elles est une technique d'apprentissage automatique appelée apprentissage par renforcement (Reinforcement Learning en anglais). Dans ce cas, les décisions correctes que prend une machine lorsqu'elle conduit une voiture - par exemple lorsqu'elle s'arrête à un feu rouge - sont récompensées à l'aide d'une fonction dite de récompense. Les chercheurs définissent les caractéristiques d'entrée sur lesquelles la machine doit baser ses décisions. Il peut s'agir, par exemple, de l'emplacement et de la vitesse des autres voitures, que la machine enregistre à l'aide d'images de caméra.
Les réseaux neuronaux profonds sont une autre approche qui a récemment été utilisée avec succès pour extraire des caractéristiques d'entrée appropriées dans diverses tâches complexes, comme les jeux vidéo ou le contrôle de robots.
La combinaison des réseaux neuronaux profonds avec la technique d'apprentissage par renforcement promet donc des effets de synergie. Cependant, ces synergies ne peuvent pas se réaliser si la machine ne "comprend pas" ce qu'est le "bon comportement", c'est-à-dire si la fonction de récompense est mal conçue.
Concevoir une bonne fonction de récompense pour la conduite autonome reste un défi. Notamment parce qu'il s'est avéré extrêmement difficile de caractériser le comportement "approprié" des conducteurs humains.
Ainsi, au lieu d'essayer de définir le "bon comportement du conducteur humain", une autre façon de libérer les synergies entre l'apprentissage par renforcement et les réseaux neuronaux profonds consiste à laisser la machine extraire elle-même ces informations.
L'apprentissage à partir de démonstrations (LfD, Learning from Demonstration en anglais) est un paradigme permettant d'apprendre à des machines à se déplacer dans un environnement sur la base d'exemples effectuées par un conducteur humain. Cela peut se faire en imitant directement le comportement du conducteur humain ou par la conception autonome d'une fonction de récompense à partir de démonstrations.
L'un des principaux défis de la LfD est l'inadéquation possible entre l'environnement du conducteur humain et celui de la machine, qui peut et a déjà causé l'échec de cette approche dans le passé [1-4].
Les pièges de l'information incomplètes…

Par exemple, des chercheurs ont utilisé des drones pour enregistrer les trajectoires de voitures conduites par des humains à partir d'une vue d'ensemble et ont utilisé ces images pour apprendre à une machine à conduire. Cependant, les drones avaient manqué des éléments cruciaux de l'environnement que les conducteurs humains avaient pris en compte dans leur conduite. Par exemple, le feu arrière des voitures n'était pas toujours visible sur les images des drones (comme le montre la figure 1).
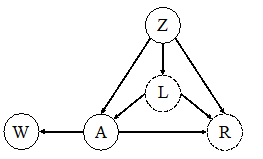
Cet environnement peut être abstrait par ce que l'on appelle un graphe causal (voir figure 2), dans lequel le conducteur tient compte de la vitesse et de la position de la voiture avant (représentée par la covariable Z) et de son feu arrière L afin de décider de l'action d'accélération A. En outre, l'action A du conducteur humain influence les vitesses et les positions des voitures à l'arrière, résumées par W.
La performance du conducteur humain est alors évaluée avec un signal de récompense latent R prenant A, L et Z comme entrées. Dans ce graphe causal, le feu arrière L a une cause directe sur l'action A et la récompense Y mais il n'est pas observable par la machine. En fait, ce signal de feu arrière peut être interprété comme un facteur de confusion caché ayant des influences directes sur l'action et la récompense. Cela peut conduire la machine à déduire des effets erronés des actions du conducteur humain (comme W), ce qui peut entraîner de mauvaises performances générales dans des environnements différents de ceux dans lesquels la machine a observé les actions du conducteur humain [2].

…et comment nous devons essayer de les éviter
Pour éviter ces problèmes, nous incorporons les relations causales sous-jacentes de l'environnement dans l'apprentissage de la machine. Ce faisant, nous cherchons à caractériser les limites théoriques d'une imitation réussie dans des systèmes qui ne sont que partiellement observables. En particulier, nous aimerions savoir quelles sont les conditions suffisantes pour garantir que les performances de la machine sont proches de celles du conducteur humain - notamment lorsque la machine conduit dans des environnements nouveaux ou qu'elle manque de certaines informations.
Notre approche consiste à caractériser d'abord le critère graphique (par exemple, s'il n'existe pas de chemin entre A et R qui contient une flèche vers A) sur le graphe causal correspondant de l'environnement, sous lequel l'apprentissage par imitation est réalisable. Deuxièmement, en exploitant le graphe causal sous-jacent, nous développerons des approches d'apprentissage par transfert causal. Cela rendra le paradigme de l'apprentissage à partir de démonstrations plus robuste face aux disparités entre les environnements de la machine et du conducteur humain.
La méthode scientifique de l'apprentissage par imitation causale
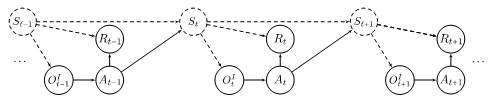
Pour formaliser le problème de l'apprentissage par imitation, nous commençons par introduire un ensemble de notations. Dans notre problème, le conducteur humain effectue sa tâche dans un environnement que nous appelons le domaine source. À l'instant t, le conducteur humain est dans l'état St. À partir de cet état, il observe OtE (il est possible que OtE =St ) et choisit en conséquence une action At et obtient une récompense Rt . Il choisit son action en utilisant une stratégie πE(At|OtE) qui est une distribution de probabilité conditionnelle sur toutes les actions possibles compte tenu de l'observation du conducteur humain.
À titre d'exemple, considérons un scénario de conduite dans lequel le conducteur humain observe sa position, celle des autres véhicules, sa vitesse, sa vitesse relative par rapport aux véhicules qui l'entourent et le feu arrière de la voiture qui le précède.
Nous désignons toutes ces variables par OtE . Supposons que les actions possibles parmi lesquelles le conducteur humain peut choisir sont l'accélération, la décélération, le maintien de sa vitesse et le virage à gauche, le virage à droite ou le maintien sur sa trajectoire.
Dans cet exemple, πE(tourner à droite, accélérer | OtE)=0,3 signifie qu'il est probable à 30 % que le conducteur humain tourne à droite et accélère, compte tenu de son observation OtE au temps t .

En tant qu'observateur, nous observons partiellement le comportement du conducteur humain dans le domaine source sur une période de longueur T . Pour être plus précis, dans notre problème, nous supposons qu'au temps 1≤t≤T, nous observons une partie de l'état du conducteur humain, noté Ot , et son action At . Par exemple, dans l'exemple de la conduite, si notre observation du comportement du conducteur humain est enregistrée par un drone, nous pouvons observer toutes les variables dans OtE, sauf le témoin lumineux de la voiture avant du conducteur humain, c'est-à-dire Ot= {l'emplacement du conducteur humain, les emplacements des autres véhicules, la vitesse du conducteur humain, la vitesse relative de ses véhicules environnants}. Dans ce cas, OtE≠Ot . Cependant, si notre observation est enregistrée par une caméra installée dans le véhicule du conducteur humain, nous avons Ot=OtE. La figure 2 représente le graphe causal qui visualise les relations entre les variables susmentionnées, c'est-à-dire OtE, At, Ot, St et Rt dans le domaine source.
Notre observation du comportement du conducteur humain est une trajectoire de longueur T qui est donnée par O1,A1,…,OT,AT et notre objectif est de concevoir une stratégie πI pour que la machine puisse imiter le comportement du conducteur humain, bien que dans un environnement différent. Nous appelons l'environnement distinct dans lequel la machine agit, le domaine cible. Dans l'environnement cible, similaire à l'environnement source, à l'instant t, la machine se trouve dans l'état St . À partir de cet état, elle observe OtI (il est possible que OtI=St ) et choisit en conséquence une action At et obtient une récompense Rt . La figure 3 représente le graphe causal des variables du domaine cible.
Stratégies pour différents scénarios
Décrivons un cadre particulier, dans lequel la machine peut imiter parfaitement le conducteur humain. Supposons que l'observation de la machine dans le domaine cible est la même que celle du conducteur humain dans le domaine source. En d'autres termes, la machine et le conducteur humain disposent du même ensemble de capteurs pour interagir avec leur environnement, c'est-à-dire que OtI=OtE. Dans ce cas, nous pouvons montrer que la stratégie optimale pour la machine consiste à estimer la stratégie du conducteur humain dans le domaine source et à l'appliquer dans l'environnement cible. Bien que la forme de la stratégie optimale soit connue, il se peut que nous ne soyons pas en mesure de l'estimer. Cela est dû au fait que notre observation du domaine source à l'instant t est limitée à Ot,At qui peut différer de l'observation du conducteur humain OtE,At dont nous avons besoin pour estimer sa stratégie. Cependant, si l'ensemble des actions et des états sont finis, alors en utilisant un ensemble d'équations linéaires, nous pouvons estimer la stratégie du conducteur humain et par conséquent obtenir la stratégie optimale pour la machine.
En général, imiter un conducteur humain signifie qu'en appliquant la stratégie que nous avons conçue (stratégie de la machine), la machine se comporte comme le conducteur humain. Étant donné une observation parfaite, nous pouvons mesurer la différence entre le conducteur humain et la machine par une mesure de distance entre deux distributions conditionnelles :
- la probabilité conditionnelle de réalisation d'actions par la machine étant donné les états du domaine cible et
- la probabilité conditionnelle d'observer le même comportement par le conducteur humain étant donné les états du domaine source.
Notre objectif ici est de sélectionner une stratégie pour la machine telle que la distance mentionnée est minimisée, c'est-à-dire que la machine conduit de manière presque identique au conducteur humain. La résolution de ce problème en général est difficile. Dans notre travail, nous visons à étudier le problème d'apprentissage par imitation ci-dessus dans différents scénarios et à trouver la stratégie optimale pour la machine ou à proposer une stratégie de remplacement qui a des performances similaires à la stratégie optimale, c'est-à-dire que la distance susmentionnée pour la stratégie de remplacement proposée est limitée par une quantité fixe.
Perspectives
Dans l'ensemble, nous visons à faire progresser notre compréhension des limites de l'imitabilité dans les systèmes d'apprentissage et à étudier la conception de LfD prouvés bons avec une application à la conduite autonome. Notre approche intègre des modèles causaux, qui nous permettent de formuler les inadéquations entre l'environnement du conducteur humain et celui de la machine, de caractériser l'imitabilité, d'identifier la stratégie d'imitation et de généraliser au-delà des paramètres aléatoires indépendants et identiquement distribués.
References:
[1] J. Etesami and P. Geiger. “Causal transfer for imitation learning and decision making under sensor-shift.” In Proceedings of the 34th AAAI Conference on Artificial Intelligence, 2020.
[2] P. de Haan, D. Jayaraman, and S. Levine. “Causal confusion in imitation learning.” In Advances in Neural Information Processing Systems, 2019.
[3] J. Zhang, D. Kumor, and E. Bareinboim. “Causal Imitation Learning with Unobserved Confounders.” In Advances in neural information processing systems, 2020.
[4] F. Codevilla, E. Santana, A. M. López, and A. Gaidon. “Exploring the limitations of behavior cloning for autonomous driving.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019.
[5] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun. “Carla: An open urban driving simulator.” In Conference on robot learning, 2017.



