What is reinforcement learning anyway?

You’ve just arrived at your hotel after a long day of travelling. You drop your bags and head to the bathroom for a refreshing shower, where you’re faced with the inevitable: an unknown shower with no markings. Sigh. What do you do?
The chances are you’ll start the shower at some intermediate tap position, and then test the temperature with your hand. Based on the result you’ll adjust the tap in the (hopefully) warmer direction if the water is too cold, or in the cooler direction if it’s too hot. You’ll keep on testing and adjusting until the temperature is just right.
Although you probably won’t be thinking this as you finally enjoy your shower, the learning cycle you’ve just been through has many of the key features of reinforcement learning, a machine learning technique that has resulted in computers that can defeat the best human Go players, cars that can drive autonomously and, to my great joy, robots that learn to vacuum your house more efficiently, the more often they do it.
There are many varieties of reinforcement learning (RL), but they all share some basic elements. The primary elements are a learner, referred to as the agent, and the environment (real or virtual) in which the learning takes place. Since the environment can change, either due to actions taken by the agent or to external factors, we need a way of describing the environment at a given time; this is the “state of the environment”. Crucially, the agent is able to interact with and affect the environment; each time it does this, it is said to be taking an action.
In our shower example, you were the agent, and the environment was the shower; every time you shifted the tap, you took an action that changed the state of the shower.
Just as you had the goal of finding the right temperature, even though you didn’t know exactly what tap position would ensure this or how even to get there, every RL agent has a goal that it needs to achieve in the environment, which it doesn’t initially know how to achieve, and which may involve uncertainty.
You probably didn’t just randomly move the tap and hope that you hit the right temperature; you had a strategy in mind that determined which way to move the tap based on its current position and the temperature your hand measured. Similarly, any agent will have a policy which they use to figure out what action they try next, based on the current state. The policy determines the behaviour of the agent; policies can range from very simple (just pick a random state) to extremely complicated.
Of course, not much learning can happen without the agent getting feedback on its actions. There are two types of feedback that the agent needs: some information about the new state, and also an indication of whether or not the new state is good (according to the goal). Computers work better with numbers, so in RL the reward is expressed as a number.
We can put the agent, environment, actions and reward together in one handy diagram:
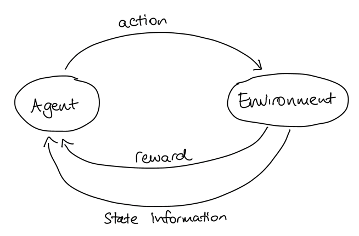
As an example, let’s look at a simple model of our shower scenario. The environment will consist of integer temperatures from 31 to 45, and the possible actions will be:
- move tap to increase temperature one degree
- move tap to decrease temperature one degree
- stay in place
Assuming that the goal is for the agent to manoeuvre the shower to the perfect temperature of 38, we can use a reward function that looks like this:
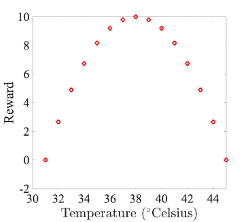
So how would learning happen in this scenario? The agent doesn’t initially know which actions to take to achieve its goal, it needs to use trial and error to investigate lots of possible states and the resulting rewards (called exploration). Thus a starting policy for our agent could be as simple as randomly picking from the possible actions[1]: the agent starts at a random state, picks a random action, moves to the state dictated by the action, updates its information with the reward for this new state, picks a new random action, moves to the new state, etc. Eventually the agent will have explored the entire state space, and will have learned which states lead to which rewards. Once our agent has uncovered the reward function, it can use this to determine a new policy: from any starting state, pick the action that leads to the state with the higher reward (called exploitation); if all actions lead to the same or lower reward, then stay in place. This will automatically lead in the quickest possible way to the correct temperature, from any starting state (hurrah for gradient descent - or in this case gradient ascent). Simple!
Unfortunately, in more complex scenarios things are a bit more complicated. It might not make sense, for example, for the agent to always choose the action that will give the highest immediate reward, because there might be actions which have a lower immediate reward, but that lead to states with even higher rewards. In chess, for example, sacrificing a piece might be necessary to set up a stronger position later. The reward function alone cannot encapsulate this kind of strategic learning. Instead, one option is to introduce the idea of a value for each state, which is roughly speaking the total reward an agent can expect to accumulate over time, starting from that state. To achieve the goal, the agent needs to choose actions that result in states that have a high value, rather than a high reward. For RL using value function estimation, the initial policy will combine exploration and exploitation, as exploitation will help the agent estimate the value function. Unfortunately, however, properly estimating the value function is tricky - the agent has to learn the value of states through many iterations of the learning scenario, continually updating its value function as it goes. There are alternatives to using a value function, the most common being policy gradients, which learn the optimal policy directly by using a neural network to map states to actions. OpenAI’s spinningup is a great place to start if you want to know more!
[1] In practice, agents usually start off with policies that combine exploration and exploitation (choosing the action that results in the highest reward), for reasons we’ll explain shortly, but for now we’ll split these steps to make the process a little clearer.
Written by Claire Blackman



