Qu'est-ce que l'apprentissage par renforcement ?

Vous venez d'arriver à votre chambre d’hôtel après une longue journée de voyage. Vous déposez vos bagages et vous vous dirigez vers la salle de bains pour prendre une douche rafraîchissante. Là, vous êtes confronté à l'inévitable : une douche inconnue sans aucune indication. Soupir. Que faire ?
Il est probable que vous démarriez la douche avec le robinet en position intermédiaire, puis que vous testiez la température avec votre main. En fonction du résultat, vous réglerez le robinet dans le sens (espéré) du chaud si l'eau est trop froide, ou dans le sens du froid si elle est trop chaude. Vous continuerez à tester et à ajuster jusqu'à ce que la température vous convienne.
Même si vous n'y pensiez probablement pas au moment de prendre votre douche, le cycle d'apprentissage que vous venez de vivre présente de nombreuses caractéristiques essentielles de l'apprentissage par renforcement (reinforcement learning en anglais). Cette technique d'apprentissage automatique a notamment à des ordinateurs de battre les meilleurs joueurs humains de Go, à des voitures de rouler de manière autonome et, à ma grande joie, à des robots d’apprendre à passer l'aspirateur plus efficacement à mesure qu’ils le font souvent.
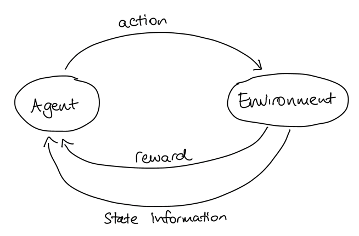
Il existe de nombreuses variantes d'apprentissage par renforcement (AR), mais elles ont toutes en commun certains éléments fondamentaux. Les éléments les plus importants sont un apprenant, appelé agent, et l'environnement (réel ou virtuel) dans lequel l'apprentissage se déroule. Étant donné que l'environnement peut changer, soit en raison des actions entreprises par l'agent, soit en raison de facteurs externes, nous avons besoin d'un moyen de décrire l'environnement à un moment donné ; c'est l'"état de l'environnement". L'agent est capable d'interagir avec l'environnement et de l'affecter ; chaque fois qu'il le fait, on dit qu'il entreprend une action.
Dans notre exemple de la douche, vous étiez l'agent et l'environnement était la douche. Chaque fois que vous tourniez le robinet, vous effectuiez une action qui modifiait l'état de la douche.
Tout comme vous aviez pour objectif de trouver la bonne température, même si vous ne saviez pas exactement quelle position du robinet vous permettrait d'y parvenir, ni même comment y parvenir, chaque agent AR a un objectif à atteindre dans l'environnement, qu'il ne sait pas initialement comment atteindre.
Vous n'avez probablement pas simplement déplacé le robinet au hasard en espérant atteindre la bonne température, mais vous aviez une stratégie en tête qui déterminait dans quelle direction le robinet devait être déplacé en fonction de sa position actuelle et de la température mesurée par votre main. De la même manière, chaque agent a une stratégie qu'il utilise pour déterminer quelle sera la prochaine action qu'il tentera de réaliser en fonction de l'état actuel. La stratégie détermine le comportement de l'agent ; les stratégies possibles peuvent être très simples (par exemple, choisir un état aléatoire) ou extrêmement compliquées.
Bien entendu, il n'est pas possible d'apprendre grand-chose si l'agent ne reçoit pas de feedback sur ses actions. Il existe deux types de feed-back dont l'agent a besoin : Des informations sur le nouvel état et des indications sur le fait que le nouvel état est bon (plus proche du but) ou non. Les améliorations donnent lieu à une récompense. Comme les ordinateurs travaillent mieux avec des chiffres, dans RL, la récompense est exprimée sous forme de nombre.
Nous pouvons résumer l'agent, l'environnement, les actions et la récompense dans un diagramme pratique :
Considérons par exemple un modèle simple pour notre scénario de douche. L'environnement est décrit à partir de températures entières de 31 à 45, et les actions possibles sont :
● Déplacer le robinet pour augmenter la température d'un degré.
● Déplacer le robinet pour abaisser la température d'un degré.
● Ne pas déplacer le robinet.
Comme objectif, nous formulons le fait que l'agent doit manœuvrer la douche à la température parfaite de 38 degrés. Pour cela, nous pouvons définir la fonction de récompense suivante :
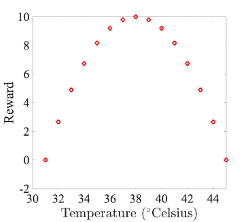
Comment se déroulerait donc l'apprentissage dans ce scénario ? Au départ, l'agent ne sait pas quelles mesures il doit prendre pour atteindre son objectif. Il doit explorer par essais et erreurs de nombreux états possibles et les récompenses qui en découlent (c'est ce qu'on appelle l'exploration). Une stratégie de départ pour notre agent pourrait donc consister à faire simplement un choix aléatoire parmi les actions possibles : l'agent commence dans un état aléatoire, choisit une action aléatoire, se déplace vers l'état défini par l'action, obtient et mémorise la récompense pour ce nouvel état. Il choisit ensuite une nouvelle action aléatoire, se déplace vers le nouvel état, etc. Finalement, l'agent aura exploré tout l'espace des états et appris quels états mènent à quelles récompenses. Une fois que notre agent a compris la fonction de récompense, il peut l'utiliser pour définir une nouvelle stratégie : A partir de chaque état initial, il choisit maintenant l'action qui mène à l'état avec la récompense la plus élevée (appelée exploitation) ; si toutes les actions mènent à la même récompense ou à une récompense inférieure, il reste à sa place. Cela conduit automatiquement à la bonne température par le chemin le plus rapide possible, et ce à partir de n'importe quel état initial (vive la méthode du gradient !). C'est simple !
Malheureusement, les choses sont un peu plus compliquées dans des scénarios plus complexes. Par exemple, il n'est pas forcément judicieux que l'agent choisisse toujours l'action dont la récompense immédiate est la plus élevée, car il peut y avoir des actions dont la récompense immédiate est plus faible, mais qui mènent à des états dont les récompenses sont encore plus élevées. Aux échecs, par exemple, il peut être nécessaire de sacrifier une pièce pour obtenir plus tard une meilleure position. La fonction de récompense seule ne peut pas représenter ce type d'apprentissage stratégique. Une possibilité consiste plutôt à introduire une valeur pour chaque état, qui correspond grosso modo à la récompense totale qu'un agent peut accumuler au fil du temps à partir de cet état. Pour atteindre l'objectif, l'agent doit choisir des actions qui mènent à des états ayant une valeur élevée et non une récompense élevée. Dans le cas d’apprentissage par renforcement avec estimation de la fonction de valeur, la stratégie initiale combinera exploration et exploitation, car l'exploitation aide l'agent à estimer la fonction de valeur. Malheureusement, il est cependant difficile d'estimer correctement la fonction de valeur - l'agent doit apprendre la valeur des états sur de nombreuses itérations, tout en mettant constamment à jour sa fonction de valeur. Il existe des alternatives à l'utilisation d'une fonction de valeur, la plus courante étant les gradients de politique, qui apprennent la stratégie optimale (« policy » en anglais) en utilisant un réseau neuronal pour inférer directement les actions à partir des états. Le site d'OpenAI est un bon point de départ si vous voulez en savoir plus !
Rédigé par Claire Blackman



