Was ist eigentlich Reinforcement Learning?

Sie sind gerade nach einem langen Reisetag in Ihrem Hotel angekommen. Sie stellen Ihr Gepäck ab und gehen ins Bad, um eine erfrischende Dusche zu nehmen. Dort erwartet Sie das Unvermeidliche: eine unbekannte Dusche ohne Markierungen. Sie seufzen. Was tun?
Die Wahrscheinlichkeit ist gross, dass Sie die Dusche bei einer Zwischenstellung des Wasserhahns starten und dann die Temperatur mit der Hand testen. Anhand des Ergebnisses werden Sie den Wasserhahn in die (hoffentlich) wärmere Richtung verstellen, wenn das Wasser zu kalt ist, oder in die kühlere Richtung, wenn es zu heiss ist. Sie testen und justieren so lange, bis die Temperatur genau richtig ist.
Auch wenn Sie wahrscheinlich nicht daran denken, während Sie endlich Ihre Dusche geniessen, weist der Lernzyklus, den Sie gerade durchlaufen haben, viele der wichtigsten Merkmale von Reinforcement Learning (auf Deutsch: Bestärkendes oder verstärkendes Lernen) auf. Diese Technik des maschinellen Lernens hat unter anderem dazu geführt, dass Computer die besten menschlichen Go-Spieler besiegen können, dass Autos autonom fahren können, und – zur grossen Freude vieler - zu Robotern, die lernen, das Haus effizienter zu saugen, je öfter sie es tun.
Es gibt viele Varianten von Reinforcement Learning (RL), aber sie alle haben einige grundlegende Elemente gemeinsam. Die wichtigsten Elemente sind ein Lernender, der als Agent bezeichnet wird, und die (reale oder virtuelle) Umgebung, in der das Lernen stattfindet. Da sich die Umgebung verändern kann, entweder durch die Aktionen des Agenten oder durch externe Faktoren, benötigen wir eine Möglichkeit, die Umgebung zu einem bestimmten Zeitpunkt zu beschreiben; dies ist der "Zustand der Umgebung". Entscheidend ist, dass der Agent in der Lage ist, mit der Umwelt zu interagieren und sie zu beeinflussen; jedes Mal, wenn er dies tut, spricht man von einer Aktion.
In unserem Beispiel mit der Dusche waren Sie der Agent, und die Umgebung war die Dusche. Jedes Mal, wenn Sie den Wasserhahn drehten, führten Sie eine Aktion durch, die den Zustand der Dusche veränderte.
So wie Sie das Ziel hatten, die richtige Temperatur zu finden, obwohl Sie nicht genau wussten, welche Einstellung dies erreichen würde oder wie Sie überhaupt dorthin gelangen konnten, hat jeder RL-Agent ein Ziel, das er etwas erreichen muss, von dem er zunächst nicht weiss, wie es zu erreichen ist.
Wahrscheinlich haben Sie den Wasserhahn nicht einfach wahllos bewegt und gehofft, dass Sie die richtige Temperatur treffen, sondern Sie hatten eine Strategie im Kopf, die auf der Grundlage der aktuellen Position des Wasserhahns und der von Ihrer Hand gemessenen Temperatur bestimmte, in welche Richtung der Wasserhahn bewegt werden sollte. In ähnlicher Weise hat jeder Agent eine Strategie, die er verwendet, um herauszufinden, welche Aktion er als Nächstes auf der Grundlage des aktuellen Zustands versucht. Die Strategie bestimmt das Verhalten des Agenten; mögliche Strategien können sehr einfach sein (z.B. einen zufälligen Zustand wählen) oder auch extrem kompliziert.
Natürlich kann nicht viel gelernt werden, wenn der Agent keine Rückmeldung über seine Handlungen erhält. Es gibt zwei Arten von Rückmeldungen, die der Agent benötigt: Informationen über den neuen Zustand und Hinweise darüber, ob der neue Zustand gut (näher am Ziel) ist oder nicht. Für Verbesserungen gibt es eine Belohnung. Da Computer besser mit Zahlen arbeiten, wird in RL die Belohnung als Zahl ausgedrückt.
Wir können den Agenten, die Umgebung, die Aktionen und die Belohnung in einem praktischen Diagramm zusammenfassen:
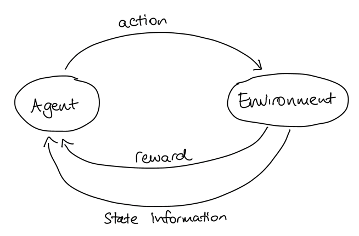
Betrachten wir als Beispiel ein einfaches Modell für unser Duschszenario. Die Umgebung wird aus ganzzahligen Temperaturen von 31 bis 45 beschrieben, und die möglichen Aktionen sind:
- Wasserhahn bewegen, um die Temperatur um ein Grad zu erhöhen.
- Wasserhahn bewegen, um die Temperatur um ein Grad zu senken.
- Wasserhahn nicht bewegen.
Als Ziel formulieren wir, dass der Agent die Dusche auf die perfekte Temperatur von 38 Grad manövrieren soll. Dafür können wir folgende Belohnungsfunktion definieren:
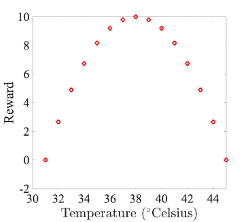
Wie würde also das Lernen in diesem Szenario ablaufen? Der Agent weiss anfangs nicht, welche Massnahmen er ergreifen muss, um sein Ziel zu erreichen. Er muss durch Versuch und Irrtum viele mögliche Zustände und die sich daraus ergebenden Belohnungen untersuchen (dies nennt man Exploration). Eine Startstrategie für unseren Agenten könnte also sein, dass er einfach eine zufällige Auswahl aus den möglichen Aktionen[1] trifft: Der Agent beginnt in einem zufälligen Zustand, wählt eine zufällige Aktion, bewegt sich in den durch die Aktion vorgegebenen Zustand, erhält und merkt sich die Belohnung für diesen neuen Zustand. Dann wählt er eine neue zufällige Aktion, bewegt sich in den neuen Zustand usw. Schliesslich wird der Agent den gesamten Zustandsraum erforscht und gelernt haben, welche Zustände zu welchen Belohnungen führen. Sobald unser Agent die Belohnungsfunktion verstanden hat, kann er diese nutzen, um eine neue Strategie festzulegen: Von jedem Ausgangszustand aus wählt er nun die Aktion, die zu dem Zustand mit der höheren Belohnung führt (Ausbeutung oder «Exploitation» genannt); wenn alle Aktionen zur gleichen oder niedrigeren Belohnung führen, bleibt er an seinem Platz. Dies führt automatisch auf dem schnellstmöglichen Weg zur richtigen Temperatur, und zwar von jedem beliebigen Ausgangszustand aus (ein Hoch auf das Gradientenverfahren!). Einfach!
Leider sind die Dinge in komplexeren Szenarien etwas komplizierter. Es ist zum Beispiel nicht unbedingt sinnvoll, dass der Agent immer die Aktion mit der höchsten unmittelbaren Belohnung wählt, weil es Aktionen geben kann, die eine geringere unmittelbare Belohnung haben, aber zu Zuständen mit noch höheren Belohnungen führen. Beim Schach zum Beispiel kann es notwendig sein, eine Figur zu opfern, um später eine bessere Stellung zu erreichen. Die Belohnungsfunktion allein kann diese Art des strategischen Lernens nicht abbilden. Stattdessen besteht eine Möglichkeit darin, für jeden Zustand einen Wert einzuführen, der grob gesagt der Gesamtbelohnung entspricht, die ein Agent ausgehend von diesem Zustand im Laufe der Zeit anhäufen kann. Um das Ziel zu erreichen, muss der Agent Aktionen wählen, die zu Zuständen führen, die einen hohen Wert und nicht eine hohe Belohnung haben. Bei RL mit Wertfunktionsschätzung wird die anfängliche Strategie Exploration und Ausbeutung kombinieren, da die Ausbeutung dem Agenten hilft, die Wertfunktion zu schätzen. Leider ist es jedoch schwierig, die Wertfunktion richtig zu schätzen - der Agent muss den Wert der Zustände über viele Iterationen lernen und dabei seine Wertfunktion ständig aktualisieren. Es gibt Alternativen zur Verwendung einer Wertfunktion, wobei die gängigste die Policy-Gradienten sind, die die optimale Strategie («Policy») erlernen, indem sie ein neuronales Netz verwenden, um von Zuständen direkt auf Aktionen zu schliessen. OpenAI's SpinningUp ist ein guter Ausgangspunkt, wenn Sie mehr wissen wollen!
[1] In der Praxis beginnen Agenten in der Regel mit Strategien, die Erkundung («Exploration», d.h. zufällige Auswahl) und Ausbeutung («Exploitation», d.h. die Auswahl der Aktion mit der höchsten Belohnung) kombinieren.
Geschrieben von Claire Blackman



