Via Automation - un breve tour sul controllo automatico: Programmazione dinamica e percorsi più brevi


Per iniziare, supponiamo che il nostro obiettivo sia trovare il percorso più breve per raggiungere la vetta, anche se a dire il vero potremmo preferire il percorso più panoramico...Affronteremo quindi il classico problema del percorso più breve e vedremo come, generalizzandolo, si ottenga un esempio fondamentale di apprendimento per rinforzo. Non a caso, questo può essere rappresentato e risolto tramite la teoria dei punti fissi, proprio come abbiamo visto in precedenza, con il nostro caffè!
Guardando verso la vetta, potremmo semplicemente calcolare la lunghezza di ogni possibile percorso, ordinare i percorsi e scegliere quello più breve. Questo sarebbe un approccio "brute-force" e funziona solo se le nostre opzioni sono limitate.
Un altro approccio è il seguente. Supponiamo di conoscere il percorso ottimale (la distanza più breve) da tutte le stazioni vicine intorno a noi. Sappiamo anche che, per raggiungere la cima, dovremo secessariamente passare per una di esse. Quindi controlliamo semplicemente la distanza da tutte quelle stazioni e aggiungiamo le rispettive distanze ottimali da quelle stazioni alla cima. La somma più piccola corrisponde al percorso ottimale. Guarda l'immagine qui sotto.
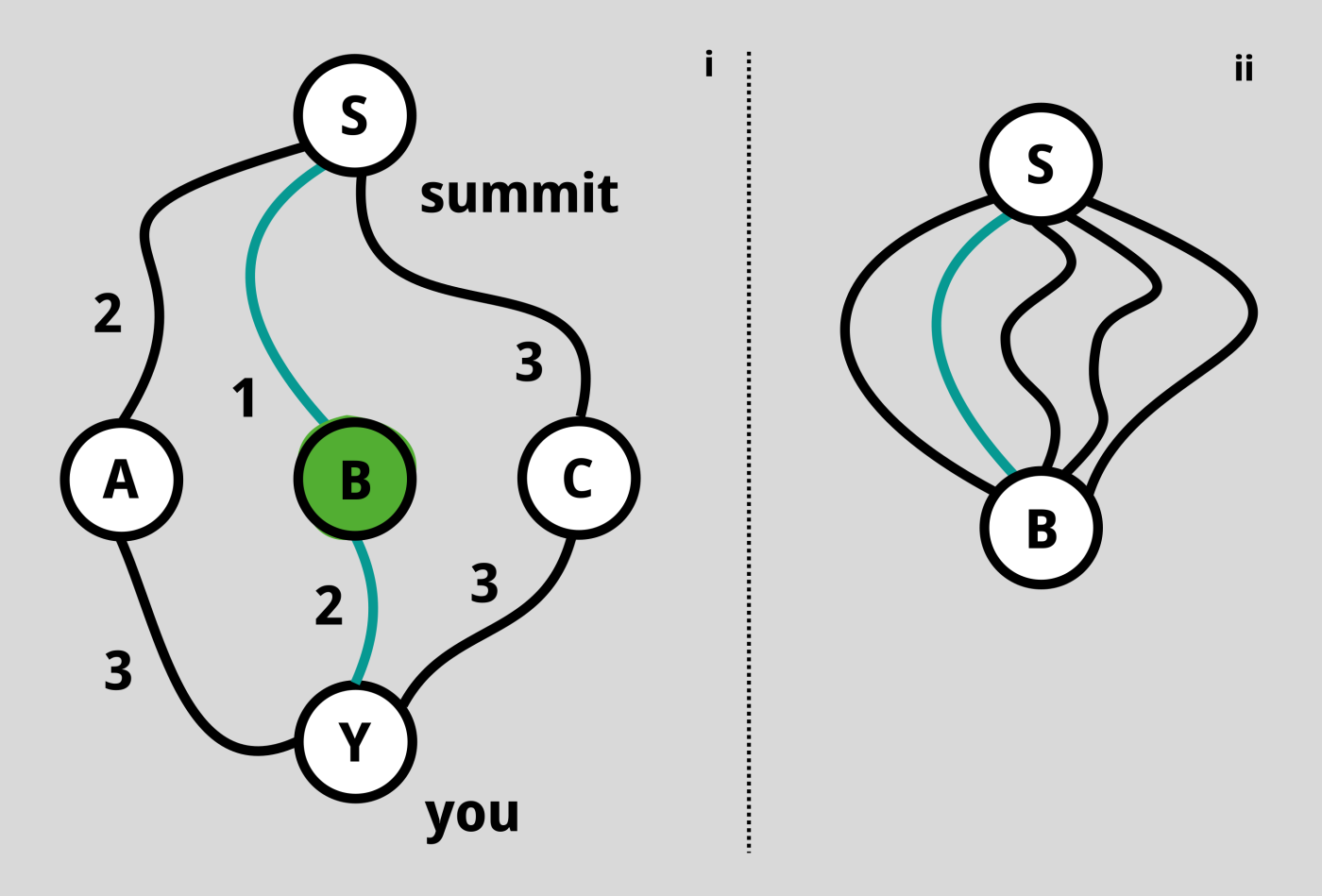
Una cosa a cui potremmo pensare ora è che ci siano molti percorsi diversi da B a S. In effetti potrebbe essere così, ma questo è irrilevante ai fini della soluzione: consideriamo solo quello più breve. Quindi, in genere, procedendo a ritroso dalla vetta, possiamo costruire il percorso più breve in modo più efficiente.
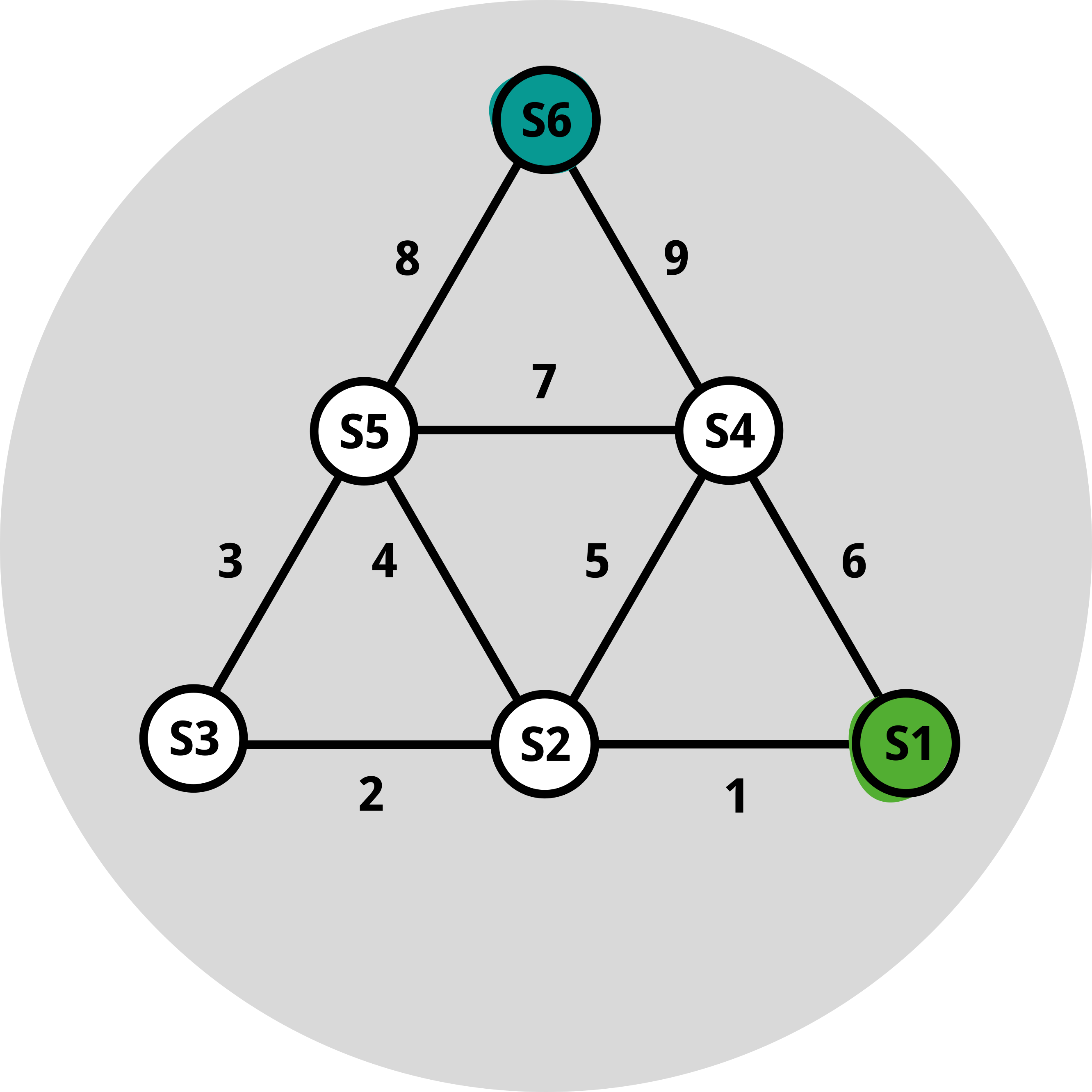
Ora, per formalizzare leggermente quanto detto sopra, indichiamo con c(i,j) la distanza da un punto i (ad esempio la nostra posizione attuale) alla stazione j (utilizziamo la lettera «c» poiché preferiamo interpretarla come un «costo»). Quindi, indichiamo con V(i) la distanza ottimale da i alla vetta. Il semplice esempio di cui sopra ci dice che, per qualsiasi punto i, questa funzione V dovrebbe soddisfare V(i) = minimo di {c(i,j) + V(j)} su tutti i j. Non sappiamo cosa sia V, ma deve soddisfare questa relazione. Poiché non conosciamo V, possiamo semplificare la notazione di cui sopra e scriverla come V=T(V), dove T è un operatore che include le distanze c e il passo di minimizzazione. Un momento, V=T(V) è esattamente una relazione di punto fisso! In effetti, i punti fissi catturano l'ottimalità in questo caso, per la cosiddetta "funzione di valore" V. Il bello è che individuare questa relazione di punto fisso ci suggerisce direttamente quali algoritmi utilizzare per trovare V. Infatti,l'algoritmo più semplice consiste nell’applicare ripetutamente la mappa T a un’ipotesi iniziale di V. Siete invitati a trovare il percorso più breve da S1 a S6 nella figura in fondo a questo post.
Va detto che per il problema del percorso più breve, di solito si ricorre all'algoritmo di Dijkstra, che è ancora oggetto di ricerca attiva [1].
Ma perché tutto questo è importante per il controllo automatico? Oltre alle evidenti applicazioni dirette ai problemi del percorso più breve, questo quadro di riferimento per la definizione ricorsiva delle azioni ottimali—introdotto da Richard Bellman e chiamato Programmazione Dinamica [2]—è la spina dorsale dell’Apprendimento per Rinforzo [3]. Nell’esempio precedente, ‘c’ era una distanza, ma cosa succederebbe se facessimo sì che questa funzione di costo si riferisse all’energia? Inoltre, cosa succederebbe se includessimo il tempo in queste rappresentazioni grafiche? Arriveremmo al cuore dell’apprendimento per rinforzo. Potreste aver visto dei video in cui i robot ‘imparano a camminare’ [4]. Lì, l’obiettivo è trovare un percorso verso una vetta (concretamente, potreste spostarvi dal punto A al punto B, all’interno di una stanza), ma ora tutto questo includerebbe anche l’imparare a camminare! Questo argomento diventa rapidamente più tecnico di quanto ci piaccia trattare in questi post, quindi rimandiamo qualsiasi lettore interessato all’autore più prolifico in questo campo: Dimitri Bertsekas [5]. Tuttavia, vorremmo sottolineare ancora una volta che l’intuizione è la stessa di prima: concettualmente, potete sostituire la vetta con un robot in piedi dall’altra parte della stanza (nel punto B, il punto di arrivo). Ciò che è diverso rispetto al nostro esempio della vetta è che nell’apprendimento per rinforzo si sa poco, e bisogna imparare ogni sorta di cose dai dati e dalla simulazione. Immaginate di cercare il percorso più breve per la vetta senza una mappa: finirete per esplorare diverse opzioni.
Ciò che colpisce, e non lo sottolineeremo mai abbastanza, è che la relazione del punto fisso è fondamentale nella maggior parte degli sviluppi moderni dell'apprendimento per rinforzo. Si tratta di un esempio straordinario di come la matematica più astratta possa avere un grande utilità pratica (se avete letto l'autobiografia di Bellman, forse questo non vi sorprenderà più di tanto). Per capire perché le cose si complicano nel contesto dei problemi di controllo automatico, tenete presente che raramente abbiamo a che fare con un numero finito di opzioni. Se vogliamo che il nostro robot cammini da A a B, quanti percorsi diversi può seguire? Di conseguenza, la funzione di valore V è solitamente un oggetto a dimensione infinita. Qualcosa su cui riflettere mentre ci avviciniamo alla vetta.
Riferimenti:
- Vedi ad esempio: https://www.quantamagazine.org/new-method-is-the-fastest-way-to-find-the-best-routes-20250806/
- Per ulteriori approfondimenti, si consiglia di ascoltare il podcast InControl dedicato a Richard Bellman: https://www.incontrolpodcast.com/1632769/episodes/16452722-ep29-richard-bellman-the-father-of-dynamic-programming oppure il recente podcast sul controllo ottimale https://www.incontrolpodcast.com/1632769/episodes/18684924-ep41-a-minimal-history-of-optimal-control. Se siete interessati alla matematica e alla ricerca in generale, date un'occhiata anche all'autobiografia di Richard Bellman https://www.worldscientific.com/worldscibooks/10.1142/0076
- Per ulteriori informazioni sull'apprendimento per rinforzo, potete iniziare da qui https://nccr-automation.ch/news/2024/what-reinforcement-learning-anyway
- Ad esempio, guarda questo video di Danijar Hafner e colleghi: https://www.youtube.com/watch?v=xAXvfVTgqr0, questo video del team di Marco Hutter: https://www.youtube.com/watch?v=8sO7VS3q8d0, o questo video di Boston Dynamics: https://youtu.be/Kf9WDqYKYQQ?si=srcuYf76gxuxYJsl. Vedi anche questo video di Geitenbeek e colleghi: https://www.youtube.com/watch? v=pgaEE27nsQw .
- Si veda ad esempio https://www.mit.edu/people/dimitrib/home.html, si veda anche il suo canale YouTube, ricco di eccellenti lezioni https://www.youtube.com/@dimitribert



