Via Automation - petit tour d'horizon du contrôle automatique: Programmation dynamique et plus courts chemins


Nous supposerons pour l'instant que notre objectif est de trouver l'itinéraire le plus court, même si nous devrions peut-être plutôt viser l'itinéraire le plus pittoresque? Plus précisément, nous aborderons d'abord un problème de plus court chemin (l'itinéraire le plus court vers le sommet). La généralisation de cet exemple conduit à un exemple de base d'apprentissage par renforcement. Par un heureux hasard, cela peut être abordé et résolu à l'aide de la théorie des points fixes, comme nous l'avons vu précédemment, dans notre café !
En regardant vers le sommet, nous pourrions simplement calculer la distance de tous les itinéraires possibles, les trier, puis sélectionner celui qui correspond au plus court chemin. Il s'agirait d'une approche exhaustive dite « par force brute » qui ne fonctionne que si nos options sont limitées.
Une autre approche est la suivante. Supposons que nous connaissions l’itinéraire optimal (la distance la plus courte) depuis toutes les stations voisines autour de nous. Nous savons également que nous devons passer par une de ces stations pour atteindre le sommet. Il suffit alors de vérifier la distance vers toutes ces stations et d’additionner les distances optimales respectives de ces stations jusqu’au sommet. La somme la plus petite correspond à l’itinéraire optimal. Voir l’image ci-dessous.
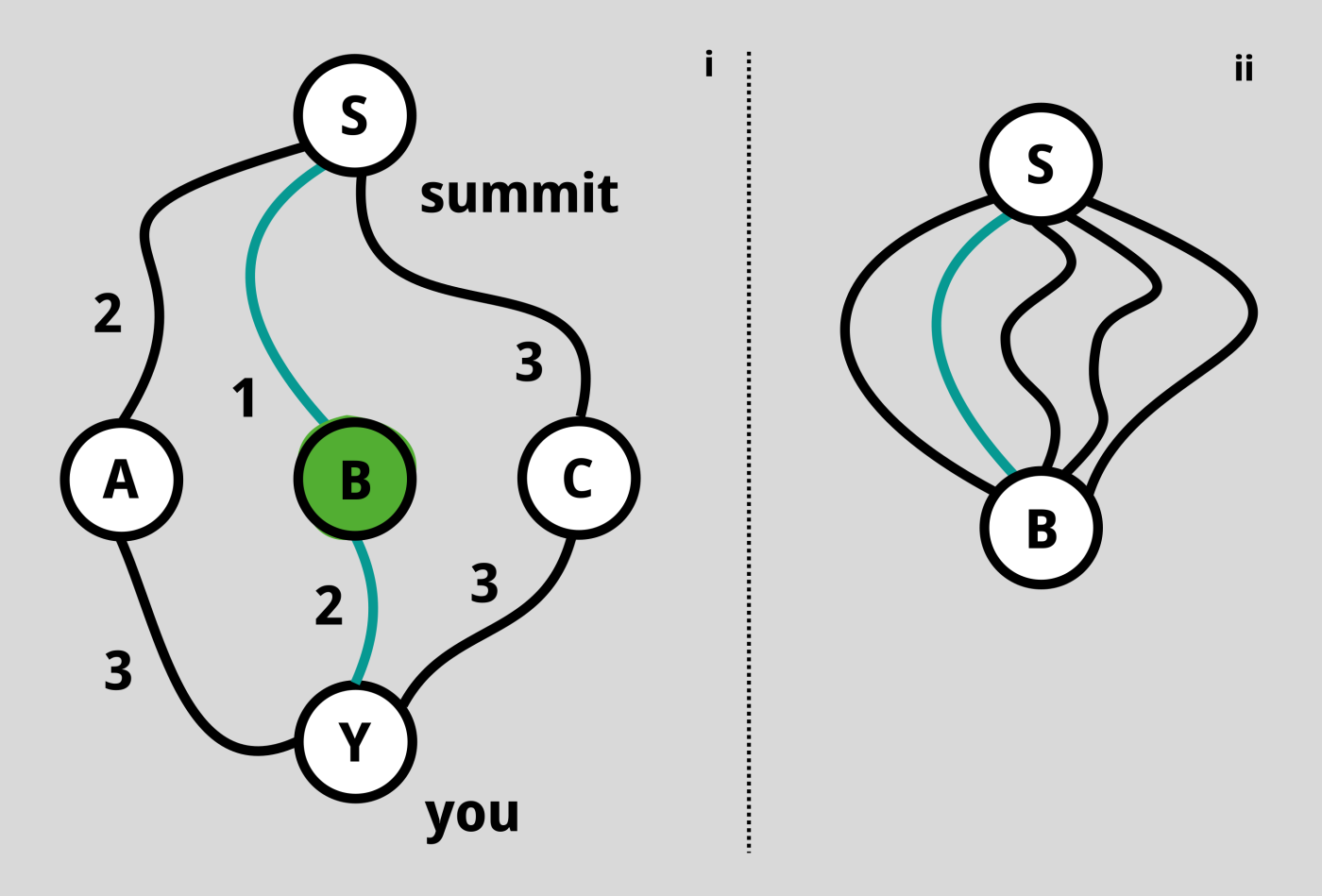
Une chose qui pourrait vous venir à l’esprit maintenant est qu’il existe peut-être de nombreux itinéraires différents entre B et S. C’est peut-être le cas, mais cela n’a aucune importance pour la solution, nous ne retenons que le plus court. Ainsi, en partant du sommet et en remontant, on peut généralement construire le plus court chemin de façon plus efficace qu’en procédant par force brute.
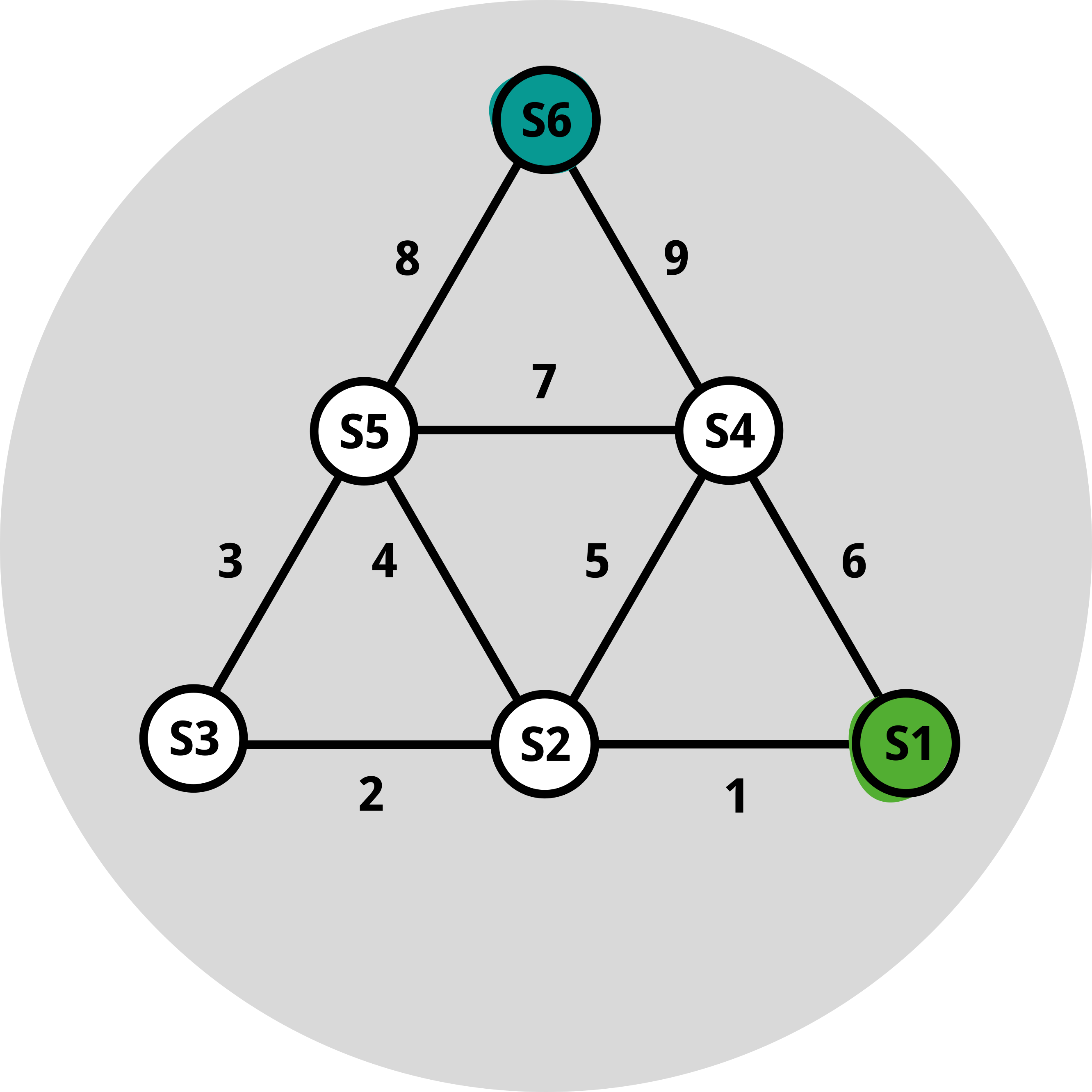
Maintenant, pour formaliser légèrement ce qui précède, désignons par c(i,j) la distance entre un point i (par exemple, notre position actuelle) et la station j (nous utilisons « c » car nous considérons cela comme un « coût »). Soit alors V(i) la distance optimale entre i et le sommet. L'exemple simple ci-dessus nous indique que, pour tout point i, cette fonction V doit satisfaire V(i) = minimum de {c(i,j) + V(j)} pour tout j. Nous ne savons pas ce qu'est V, mais elle doit satisfaire cette relation. Comme nous ne connaissons pas V, nous pouvons simplifier la notation ci-dessus et l'écrire sous la forme V=T(V), où T est un opérateur qui inclut les distances c et l'étape de minimisation. Attendez un instant, V = T(V) est exactement une relation de point fixe ! En effet, les points fixes capturent ici l'optimalité, dans le cas de la « fonction de valeur » V. La beauté réside dans le fait que l'identification de cette relation de point fixe nous oriente vers des algorithmes appropriés pour trouver V. En fait, l'algorithme le plus simple se résume à appliquer itérativement l'opérateur T à une estimation initiale de V. Nous vous invitons à trouver le plus court chemin de S1 à S6 dans la figure au bas de cet article. Il convient de préciser que pour le problème du plus court chemin, on a généralement recours à l’algorithme de Dijkstra, qui fait encore l’objet d’études actives [1].
Mais en quoi cela concerne-t-il la commande automatique ? Outre les applications directes évidentes aux problèmes de plus court chemin, ce cadre de définition récursive des actions optimales, mis au point par Richard Bellman et appelé programmation dynamique [2], constitue la colonne vertébrale de l'apprentissage par renforcement [3]. Dans l'exemple ci-dessus, « c » représentait une distance, mais que se passerait-il si nous faisions en sorte que cette fonction de coût soit liée à l'énergie ? De plus, que se passerait-il si nous incluions le temps dans ces graphes ? Nous arriverions alors au cœur de l'apprentissage par renforcement. Vous avez peut-être vu des vidéos dans lesquelles des robots « apprennent à marcher » [4]. Dans ce cas, l’objectif est de trouver un itinéraire vers un sommet (concrètement, on pourrait se déplacer du point A au point B, à l’intérieur d’une pièce), mais tout cela inclut désormais aussi l’apprentissage de la marche ! Cela devient rapidement plus technique que ce que nous souhaitons aborder dans ces articles; nous renvoyons donc tout lecteur intéressé à l’auteur le plus prolifique dans ce domaine: Dimitri Bertsekas [5]. Néanmoins, nous tenons à souligner à nouveau que l’intuition est la même qu’auparavant: conceptuellement, vous pouvez remplacer le sommet par un robot se tenant de l’autre côté de la pièce (au point B, le point d’arrivée). Ce qui diffère de notre exemple du sommet, c’est que dans l’apprentissage par renforcement, on en sait peu, et vous devez apprendre toutes sortes de choses à partir des données et de la simulation. Imaginez que vous essayez de trouver le plus court chemin vers le sommet, sans carte: vous finirez par explorer plusieurs options.
Ce qui est frappant, et on ne le soulignera jamais assez, c’est que la relation de point fixe joue un rôle central dans la plupart des développements modernes de l’apprentissage par renforcement. C’est là un exemple remarquable de l’utilité pratique considérable que peuvent avoir des mathématiques plus abstraites (si vous avez lu l’autobiographie de Bellman, cela vous surprendra peut-être moins). Pour comprendre pourquoi les choses se compliquent dans le contexte des problèmes de commande automatique, notez que nous travaillons rarement avec un nombre fini d’options. Si nous voulons que notre robot se déplace de A à B, combien d’itinéraires différents peut-il emprunter ? De ce fait, la fonction de valeur V est généralement un objet de dimension infinie. Voilà de quoi réfléchir pendant notre ascension vers ce sommet.
Références:
- Voir par exemple : https://www.quantamagazine.org/new-method-is-the-fastest-way-to-find-the-best-routes-20250806/
- Pour en savoir plus, écoutez le podcast InControl consacré à Richard Bellman : https://www.incontrolpodcast.com/1632769/episodes/16452722-ep29-richard-bellman-the-father-of-dynamic-programming ou le récent podcast sur la commande optimale https://www.incontrolpodcast.com/1632769/episodes/18684924-ep41-a-minimal-history-of-optimal-control. Si vous vous intéressez plus largement aux mathématiques et à la recherche, pensez également à l'autobiographie de Richard Bellman https://www.worldscientific.com/worldscibooks/10.1142/0076
- Pour en savoir plus sur l'apprentissage par renforcement, vous pouvez commencer par consulter cette page https://nccr-automation.ch/news/2024/what-reinforcement-learning-anyway
- Par exemple, regardez cette vidéo de Danijar Hafner et ses collègues : https://www.youtube.com/watch?v=xAXvfVTgqr0, cette vidéo de l'équipe de Marco Hutter : https://www.youtube.com/watch?v=8sO7VS3q8d0, ou cette vidéo de Boston Dynamics : https://youtu.be/Kf9WDqYKYQQ?si=srcuYf76gxuxYJsl. Voir également cette vidéo de Geitenbeek et ses collègues : https://www.youtube.com/watch? v=pgaEE27nsQw .
- Voir par exemple https://www.mit.edu/people/dimitrib/home.html, consultez également sa chaîne YouTube, qui regorge d'excellentes conférences : https://www.youtube.com/@dimitribert



