Via Automation – ein kurzer Überblick über die Regelungstechnik: Dynamische Programmierung und kürzeste Wege


Wir gehen vorerst davon aus, dass unser Ziel darin besteht, die kürzeste Route zu finden. Oder sollten wir vielleicht doch eher die landschaftlich reizvollste Route anstreben? Genauer gesagt besprechen wir zunächst ein Kürzeste-Wege-Problem (den kürzesten Weg zum Gipfel). Die Verallgemeinerung dieses Beispiels führt zu einem grundlegenden Beispiel für bestärkendes Lernen. Wie wir zuvor anhand unseres Kaffee-Beispiels gesehen haben, lässt sich dies mithilfe der Fixpunkttheorie erfassen und lösen!
Mit Blick auf den Gipfel könnten wir einfach die Distanzen aller möglichen Routen berechnen, diese sortieren und die Route auswählen, die dem kürzesten Weg entspricht. Dies wäre ein «Brute-Force»-Ansatz und funktioniert nur, wenn unsere Optionen begrenzt sind.
Ein anderer Ansatz sieht wie folgt aus: Angenommen, wir kennen die optimale Route (die kürzeste Entfernung) von allen benachbarten Stationen um uns herum. Wir wissen auch, dass wir eine solche Station passieren müssen, um den Gipfel zu erreichen. Dann prüfen wir einfach die Entfernung zu all diesen Stationen und addieren die jeweiligen optimalen Entfernungen von diesen Stationen zum Gipfel. Die kleinste Summe entspricht der optimalen Route. Siehe die Abbildung unten.
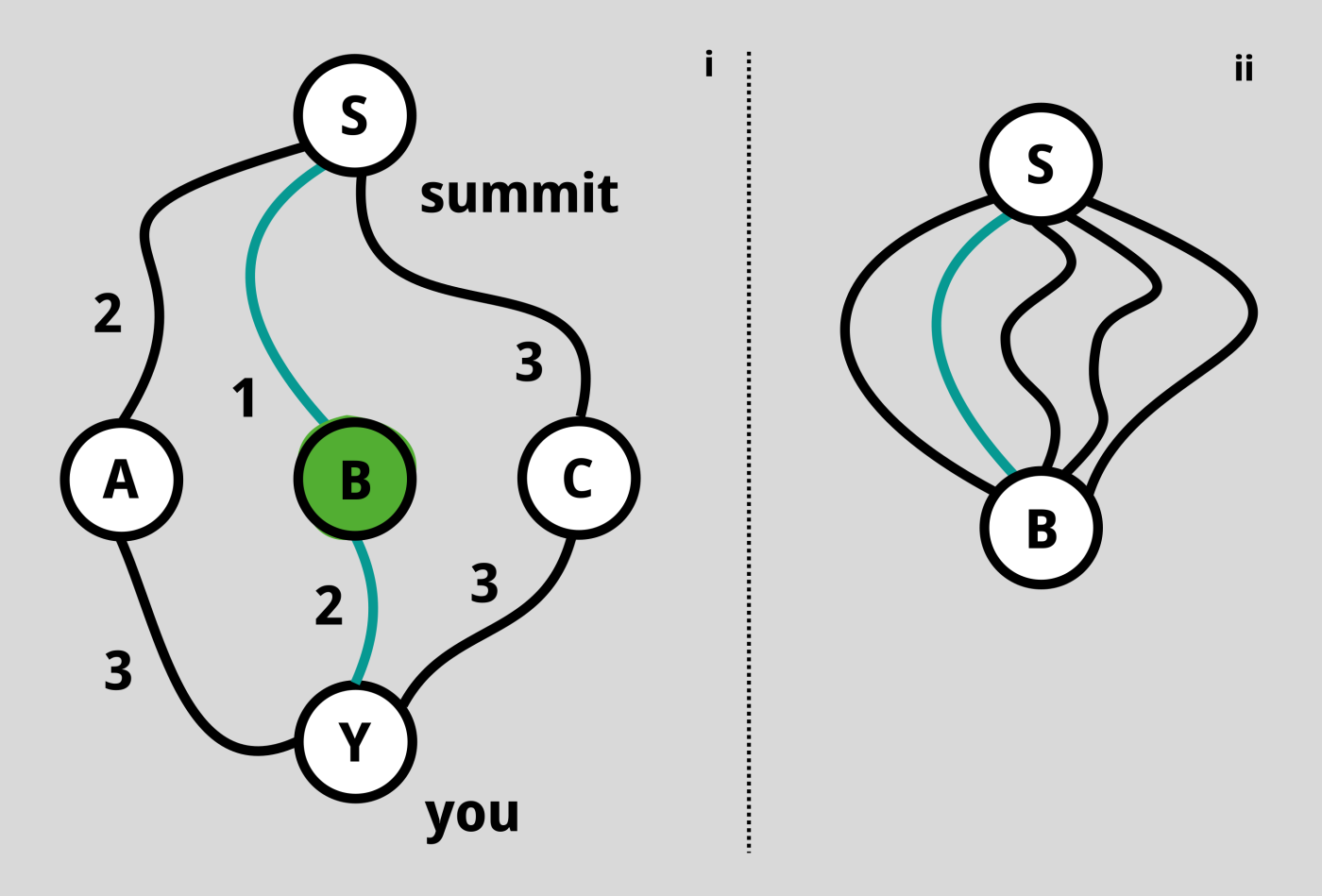
Man könnte nun denken, dass es vielleicht viele verschiedene Routen von B nach S gibt. Das mag zwar zutreffen, ist für die Lösung jedoch irrelevant, da wir nur den kürzesten Weg betrachten. Daher können wir den kürzesten Weg in der Regel effizienter als mit einem Brute-Force-Ansatz konstruieren, indem wir vom Gipfel aus rückwärts vorgehen.
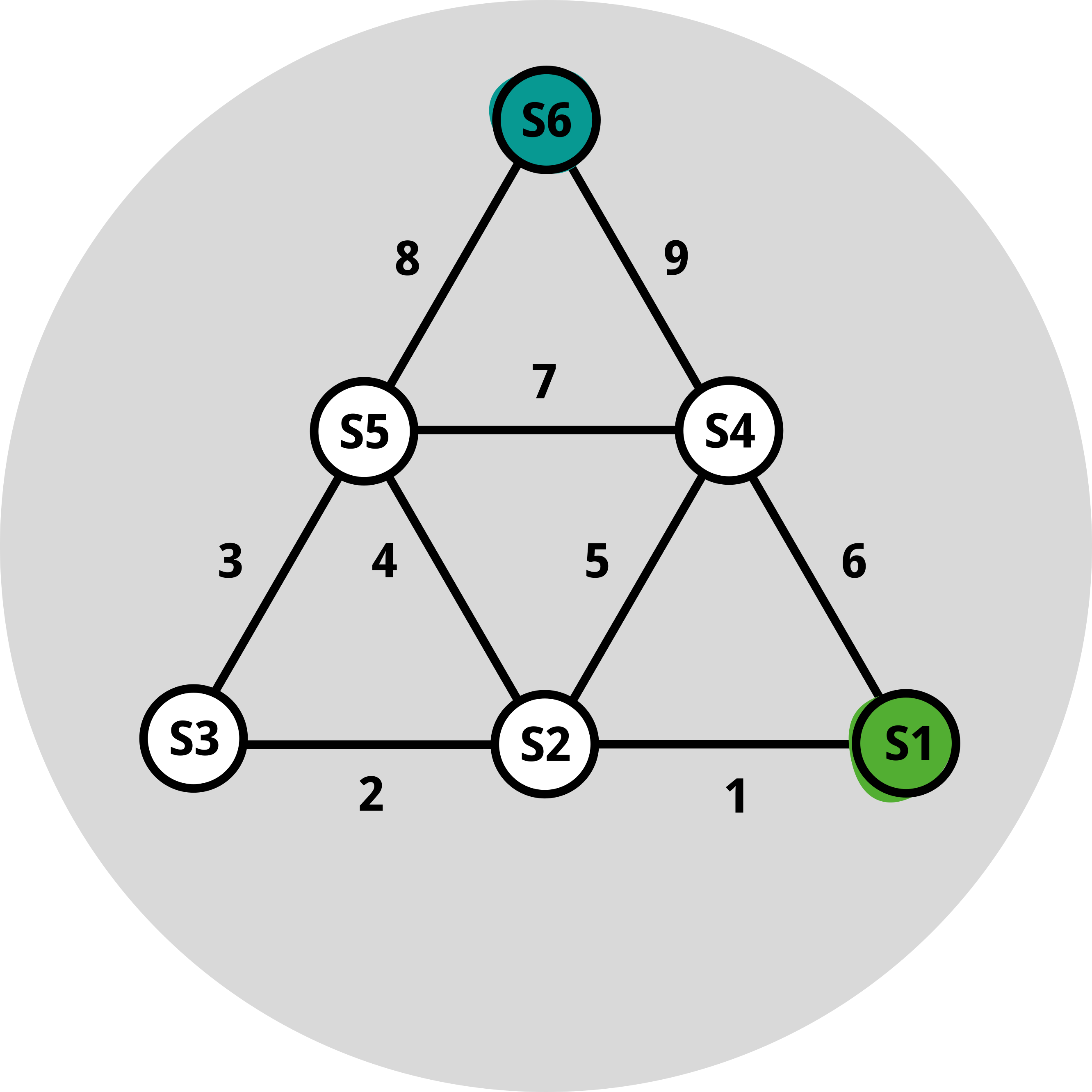
Um das Obige nun etwas zu formalisieren, bezeichnen wir mit c(i,j) die Entfernung von einem Punkt i (z. B. unserem aktuellen Standort) zur Station j (wir verwenden «c», da wir dies als «Kosten», engl.: «cost», verstehen möchten). Dann sei V(i) die optimale Entfernung von i zum Gipfel. Das einfache Beispiel von oben sagt uns, dass für jeden Punkt i diese Funktion V die Bedingung V(i) = Minimum von {c(i,j) + V(j)} über alle j erfüllen muss. Wir wissen nicht, was die Funktion V ist, aber sie muss diese Beziehung erfüllen. Da wir V nicht kennen, können wir die obige Notation vereinfachen und sie als V=T(V) schreiben, wobei T ein Operator ist, der die Abstände c und den Minimierungsschritt beinhaltet. Moment mal, V = T(V) ist genau eine Fixpunktrelation! Tatsächlich erfassen Fixpunkte hier die Optimalität, in diesem Fall der sogenannten «Wertfunktion» V. Das Schöne daran ist, dass uns diese Fixpunktrelation direkt zu geeigneten Algorithmen führt, um V zu finden. Der einfachste Algorithmus läuft darauf hinaus, die Abbildung T iterativ auf einen Startwert für V anzuwenden. Versuchen Sie doch einmal, den kürzesten Weg von S1 nach S6 in der Abbildung am Ende dieses Beitrags zu finden.
Es sei angemerkt, dass man für das Kürzeste-Wege-Problem üblicherweise auf den Dijkstra-Algorithmus zurückgreift, der nach wie vor aktiv erforscht wird [1].
Warum ist dies nun für die Regelungstechnik relevant? Abgesehen von offensichtlichen direkten Anwendungen von Kürzeste-Wege-Problemen ist dieser Ansatz der rekursiven Definition optimaler Aktionen – von Richard Bellman entwickelt und als Dynamische Programmierung [2] bezeichnet – das Rückgrat des bestärkenden Lernens [3]. Im obigen Beispiel war «c» eine Distanz, aber was wäre, wenn diese Kostenfunktion den Energieverbrauch abbilden würde? Und was wäre, wenn wir die benötigte Zeit in diese grafischen Darstellungen einbeziehen würden? Wir würden zum Kern des bestärkenden Lernens gelangen. Vielleicht haben Sie schon Videos gesehen, in denen Roboter «laufen lernen» [4]. Dort ist das Ziel ähnlich: einen Weg zu finden, etwa von Punkt A nach Punkt B in einem Raum; zugleich muss der Roboter aber auch das Laufen selbst lernen! Das wird schnell technischer, als wir es in diesen Beiträgen behandeln möchten, daher verweisen wir interessierte Leserinnen und Leser auf einen der produktivsten Autoren auf diesem Gebiet: Dimitri Bertsekas [5]. Dennoch möchten wir noch einmal betonen, dass die Grundidee dieselbe ist wie zuvor: Konzeptionell können Sie den Gipfel (als Ziel) dadurch ersetzen, dass ein Roboter auf die andere Seite des Raumes gelangen soll (zu Punkt B, dem Endpunkt). Der Unterschied zu unserem Gipfelbeispiel besteht darin, dass beim bestärkenden Lernen nur wenig bekannt ist und man vieles aus Daten und Simulationen lernen muss. Stellen Sie sich vor, Sie versuchen, den kürzesten Weg zum Gipfel zu finden, ohne eine Karte zu haben – Sie werden unweigerlich mehrere Optionen ausprobieren müssen.
Besonders bemerkenswert ist – und wir können dies gar nicht genug betonen – dass die Fixpunktrelation bei den meisten modernen Entwicklungen im Bereich des bestärkenden Lernens eine zentrale Rolle spielt. Dies ist ein eindrucksvolles Beispiel dafür, dass abstrakte Mathematik von grossem praktischem Nutzen sein kann (wer Bellmans Autobiografie gelesen hat, für den ist dies vielleicht weniger überraschend). Um zu verstehen, warum die Dinge im Zusammenhang mit regelungstechnischen Problemen komplizierter werden, sollte man bedenken, dass wir selten mit einer endlichen Anzahl von Optionen arbeiten. Wenn wir wollen, dass sich unser Roboter von A nach B bewegt, wie viele verschiedene Wege kann er nehmen? Daher ist die Wertfunktion V in der Regel ein unendlichdimensionales Objekt. Darüber lässt sich auf dem Weg zum Gipfel nachdenken.
Referenzen:
- Siehe zum Beispiel: https://www.quantamagazine.org/new-method-is-the-fastest-way-to-find-the-best-routes-20250806/
- Weitere Hintergrundinformationen finden Sie im InControl-Podcast über Richard Bellman: https://www.incontrolpodcast.com/1632769/episodes/16452722-ep29-richard-bellman-the-father-of-dynamic-programming oder im aktuellen Podcast zur optimalen Regelung https://www.incontrolpodcast.com/1632769/episodes/18684924-ep41-a-minimal-history-of-optimal-control. Wenn Sie sich allgemein für Mathematik und Forschung interessieren, sollten Sie auch einen Blick in die Autobiografie von Richard Bellman werfen https://www.worldscientific.com/worldscibooks/10.1142/0076
- Wenn Sie mehr über bestärkendes Lernen erfahren möchten, können Sie hier beginnen: https://nccr-automation.ch/news/2024/what-reinforcement-learning-anyway
- Sehen Sie sich zum Beispiel dieses Video von Danijar Hafner und Kollegen an: https://www.youtube.com/watch?v=xAXvfVTgqr0, dieses Video von Marco Hutters Team: https://www.youtube.com/watch?v=8sO7VS3q8d0, oder dieses Video von Boston Dynamics: https://youtu.be/Kf9WDqYKYQQ?si=srcuYf76gxuxYJsl. Siehe auch dieses Video von Geitenbeek und Kollegen: https://www.youtube.com/watch? v=pgaEE27nsQw .
- Siehe zum Beispiel https://www.mit.edu/people/dimitrib/home.html, sehen Sie sich auch seinen YouTube-Kanal an, der voller hervorragender Vorträge ist https://www.youtube.com/@dimitribert



