Wie Regelungstechnik die Polarisierung auf sozialen Netzwerken verringern kann


Sprechen wir über ein Wort, das uns allen unangenehm ist: „Doomscrolling”. Im Zeitalter der rasanten Informationsverbreitung auf sozialen Medien ist dies leider etwas, was wir alle in unserer Freizeit tun. Wenn Sie das nächste Mal gedankenlos durch Instagram oder TikTok scrollen, möchte ich Sie alle dazu ermutigen, darüber nachzudenken, wie diese Apps Sie süchtig machen.
Jede Social-Media-Plattform verfügt über einen integrierten „Empfehlungsalgorithmus”, der Ihre Aktivitäten auf dieser Plattform verfolgt (z. B. die Zeit, die Sie auf einem bestimmten Video verbracht haben, Likes/Dislikes, Kommentare usw.) und versucht, Ihre Interessen einzuschätzen. Basierend auf diesen Aktivitäten spuckt der Algorithmus neue Beiträge aus, mit denen Sie sich höchstwahrscheinlich wieder beschäftigen werden. Dies bezeichnen wir in der künstlichen Intelligenz (KI) als „überwachtes Lernen”.
Der bewährte Weg, um Nutzer bei der Stange zu halten, besteht also darin, ihnen mehr von dem zu geben, worauf sie reagieren: So einfach ist das. Kein Wunder, dass Google und Meta jedes Jahr Milliarden mit sozialen Medien verdienen. Aber diese Algorithmen haben auch eine Schattenseite, deren erste Opfer sind wir, die Nutzer.
Polarisierende Beiträge haben Sie an Ihre Smartphones gefesselt
Ja, und wahrscheinlich merken Sie es nicht einmal. Social-Media-Unternehmen verdienen nur dann viel Geld, wenn Sie endlos durch Ihr Smartphone scrollen ... was weniger wahrscheinlich ist, wenn sie nuancierte Beiträge vorschlagen. Leider bedeutet dies, dass der Algorithmus überwiegend extreme Inhalte fördert, um ein hohes Engagement aufrechtzuerhalten. Im Vorfeld der US-Wahlen 2024 habe ich dies selbst miterlebt, als mir Beiträge auf X (ehemals Twitter) auffielen, die entweder die Demokraten oder die Republikaner extrem favorisierten und oft die andere Partei so sehr verteufelten, dass es beunruhigend war, dies mit anzusehen. Da sich dank ihrer eingängigen und provokanten Überschriften (oft gemischt mit unbestätigten Fake News) immer mehr Nutzer mit solchen Artikeln beschäftigen, erhalten diese Beiträge mehr Sichtbarkeit, was dazu führt, dass immer mehr Menschen diese Artikel zu sehen bekommen.

Aber warum lesen die Menschen diese Artikel überhaupt, oder beschäftigen sich sogar mit ihnen? Wir alle zeigen eine „Bestätigungsverzerrung”, die Tendenz, Gedanken und Verhaltensweisen zu verstärken, die unseren bestehenden Überzeugungen entsprechen. Wir alle haben unsere eigene Meinung zu den täglichen Geschehnissen, und der Empfehlungsalgorithmus ist intelligent genug, diese für seine eigenen Zwecke zu nutzen. Da uns der Empfehlungsalgorithmus immer wieder Artikel zeigt, die unsere bisherigen Überzeugungen bestätigen, werden wir wahrscheinlich noch mehr von unserer ursprünglichen Position zu einem Thema überzeugt, was zur Bildung von „Blasen” und „Echokammern” führt. Auf gesellschaftlicher Ebene führt dies zu einer Polarisierung; wie gefährlich das ist, kann gar nicht genug betont werden.
Das drängende Problem besteht darin, dass moderne Empfehlungsalgorithmen tatsächlich so konzipiert sind, dass sie durch Sichtbarkeit den Gewinn maximieren (auch wenn die Milliardenunternehmen etwas anderes behaupten) und damit die soziale Harmonie stören. Ein noch bedenklicherer Aspekt ist, dass sich Fake News unbemerkt in Algorithmen einschleichen und die Entwickler von Algorithmen möglicherweise ihre eigenen Ziele verfolgen.
Angesichts dieses Problems wollten wir vom Institut für Automatik und NCCR Automation herausfinden, ob es möglich ist, Empfehlungsalgorithmen zu entwickeln, die ein hohes Engagement aufrechterhalten, ohne die Gesellschaft zu polarisieren, und die gute Nachricht ist, dass wir möglicherweise eine Lösung gefunden haben!
Engagement und Polarisierung in Einklang bringen
Stellen Sie sich vor, Sie möchten einen Laptop online kaufen. Normalerweise würden wir unsere Freunde und Kollegen nach ihrer Meinung zu diesem Laptop fragen und dann eine Entscheidung treffen. Ähnlich verhält es sich, wenn wir online interessante Nachrichten lesen: Wir diskutieren sie mit unseren Kollegen beim Mittagessen und bilden uns dann eine Meinung zu diesem Thema. Unser Netzwerk spielt also eine wichtige Rolle bei der Entscheidungsfindung, insbesondere online.
Leider berücksichtigen die Empfehlungssysteme der großen Social-Media-Unternehmen, die KI einsetzen, dieses Netzwerk nicht explizit. Zwar verfolgen die Algorithmen, mit wem Sie in den sozialen Medien verbunden sind und welche Aktivitäten Sie dort ausüben, aber sie nutzen diese Informationen nicht konstruktiv. Die meisten Algorithmen geben der „Personalisierung” (d. h. Ihrer Interaktion mit der Plattform) eine überwältigende Priorität gegenüber der „Netzwerkwahrnehmung” (d. h. Ihrer Interaktion mit anderen auf der Plattform).
Da die Polarisierung von Gesellschaften und die Bildung von Blasen eher ein Netzwerkphänomen sind (und nicht nur auf Personalisierung zurückzuführen sind), hatten wir die Intuition, dass wir das Netzwerk explizit nutzen könnten, um die Polarisierung zu verringern, während wir weiterhin personalisierte Algorithmen einsetzen, um die Interaktion zu erhöhen. Dies bezeichnen wir als „netzwerkbewusstes” Empfehlungssystem.
Um diese spezielle Aufgabe zu lösen, haben wir ein Optimierungsproblem entwickelt, das wie folgt aussieht:
Maximierung Zielfunktion (Interaktion – Polarisierung)
unter Berücksichtigung von Nebenbedingungen (Meinungsdynamik)
In einem typischen Optimierungsproblem gibt es eine Zielfunktion, die ein „Ziel” darstellt (in diesem Zusammenhang die Maximierung des Engagements bei gleichzeitiger Minimierung der Polarisierung), sowie Nebenbedingungen, die Sie daran hindern können, die beste Lösung zu finden. In diesem Zusammenhang handelt es sich um die zeitliche Entwicklung von Meinungen in einem geschlossenen Kreislauf mit den empfohlenen Artikeln und dem Einfluss anderer Nutzer.
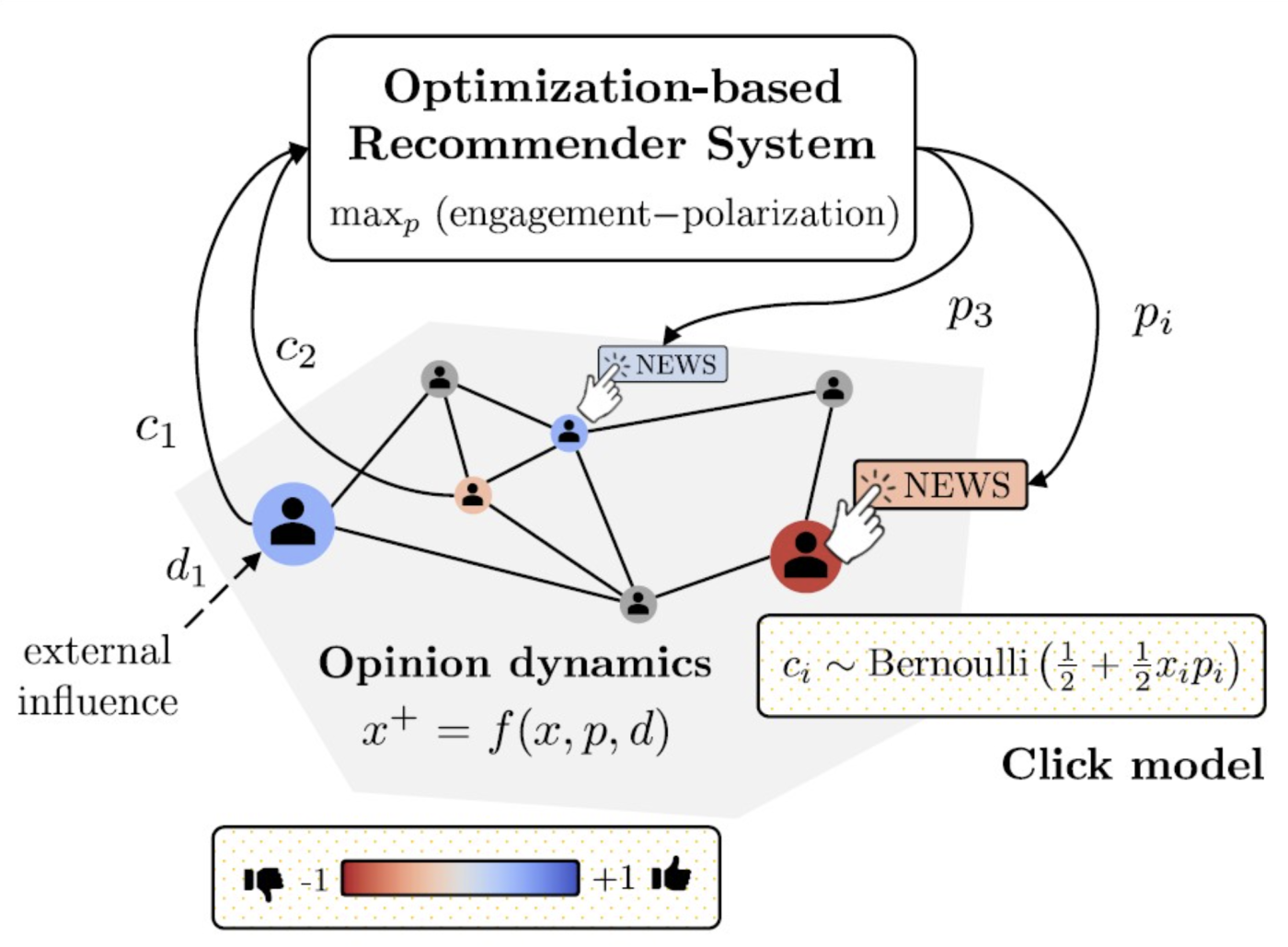
Was sind die Herausforderungen bei der Entwicklung eines solchen Algorithmus?
Jeder Empfehlungsalgorithmus kann Ihre Präferenzen lernen und mithilfe gut entwickelter KI-Tools entsprechend optimieren. Daher ist der Teil der Engagement-Maximierung nicht allzu schwer zu lösen. Die Minimierung der Polarisierung bedeutet jedoch, dass der Empfehlungsdienst wissen sollte, wo Sie stehen (z. B. auf einer Skala von -1 bis +1, wobei +1 bedeutet, dass Sie stark zu den Demokraten neigen, und -1, dass Sie stark für die Republikaner sind) und wie gut Sie mit Ihrem Netzwerk verbunden sind. Dies ist nicht trivial zu ermitteln.
In einer realistischen Situation werden Sie X oder Instagram nicht ausdrücklich mitteilen, dass Sie eine Seite der anderen vorziehen, und diese werden Sie auch nicht danach fragen. Eine solche eindeutige Verletzung der Privatsphäre würde Empörung hervorrufen (obwohl einige Algorithmen ihre eigenen frechen Methoden haben, um dies herauszufinden). Sie werden Ihnen auch nicht mitteilen, wessen Meinung Sie in Ihrem Netzwerk am meisten schätzen oder wen Sie am meisten hassen. Darüber hinaus kennt die Social-Media-Plattform Ihre Präferenzen beim Lesen von Artikeln nicht. Beispielsweise lesen Sie vielleicht lieber Artikel aus dem Tagesanzeiger als aus dem NZZ.
Daher sind Ihre Echtzeit-Meinungen, wie Sie Ihr soziales Netzwerk wahrnehmen und wie Sie Artikel betrachten, d. h. Ihr Klickverhalten, dem Algorithmus a priori unbekannt.
Ein „netzwerkbewusster” Algorithmus hilft uns enorm!
Wir verwenden eine Kombination aus Standard-Schätzalgorithmen aus der Regelungstechnik und neuronalen Netzen, um diese Probleme zu lösen, und setzen „Online Feedback Optimization” (OFO) ein, ein sehr praktisches Tool (ebenfalls von Forschern des NCCR Automation entwickelt!), um das Optimierungsproblem in zu lösen.
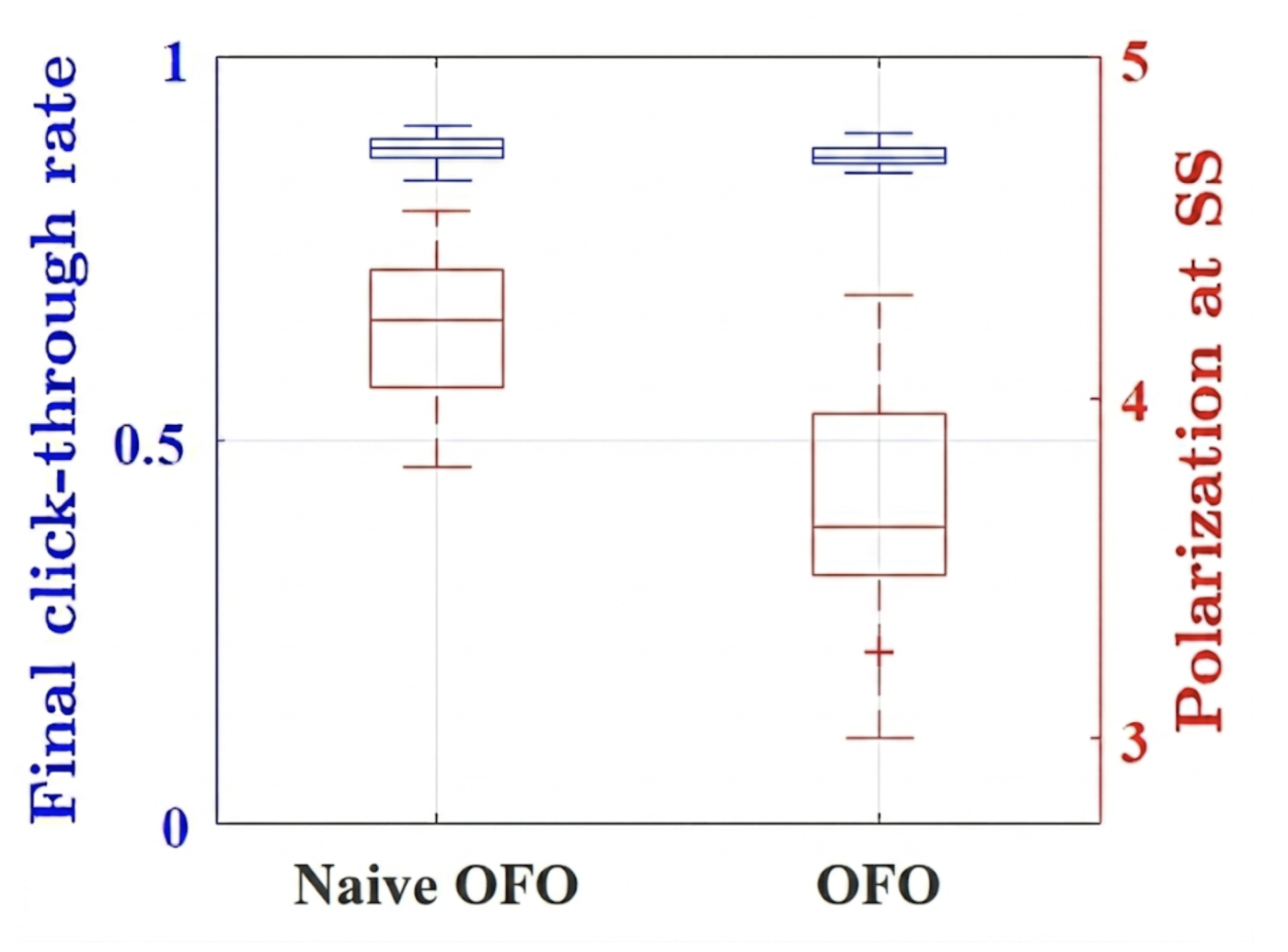
Nach einigen Simulationen und einem Vergleich mit einem „naiven” Fall (bei dem nur die Personalisierung das Ziel war und das Netzwerk ignoriert wurde) konnten wir zeigen, dass unser Algorithmus viel besser funktioniert, um ein hohes Maß an Engagement aufrechtzuerhalten und gleichzeitig die Polarisierung in sozialen Netzwerken zu verringern (siehe Abbildung 2).
Unsere empirischen Ergebnisse zeigen im Wesentlichen, dass man das Engagement auf Social-Media-Plattformen nicht opfern muss, um die Polarisierung zu minimieren. Wir hoffen aufrichtig, dass die großen Plattformen in Zukunft ihre Algorithmen zugunsten „sicherer” Designs ändern, die eine geringere Radikalisierung fördern und aktiv auf das dringende Ziel der Verringerung der Polarisierung in sozialen Netzwerken hinarbeiten.
Readers can find a complete technical and rigorous explanation of our algorithm here.
*”Steady-state” in control theory is just a euphemism that represents the end of a simulation.



